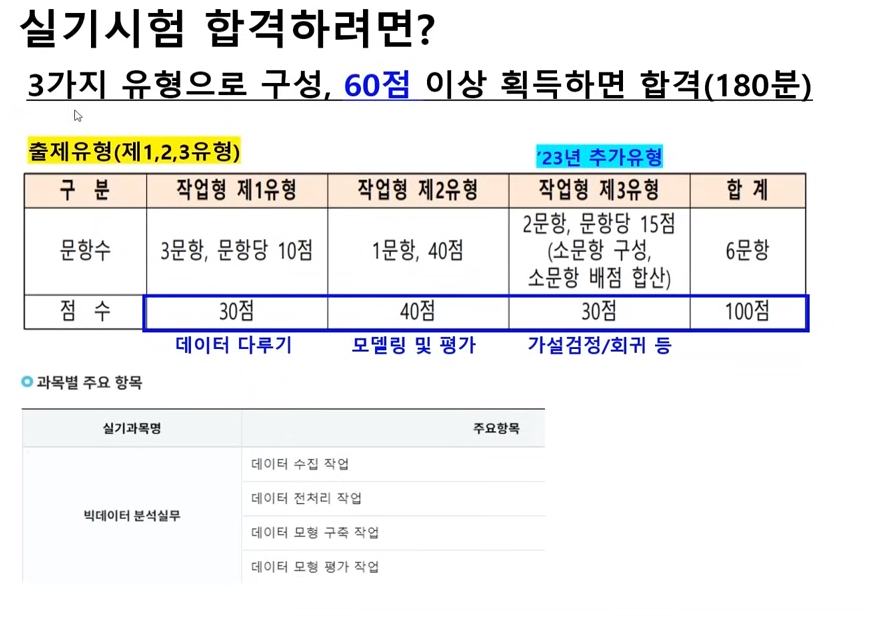
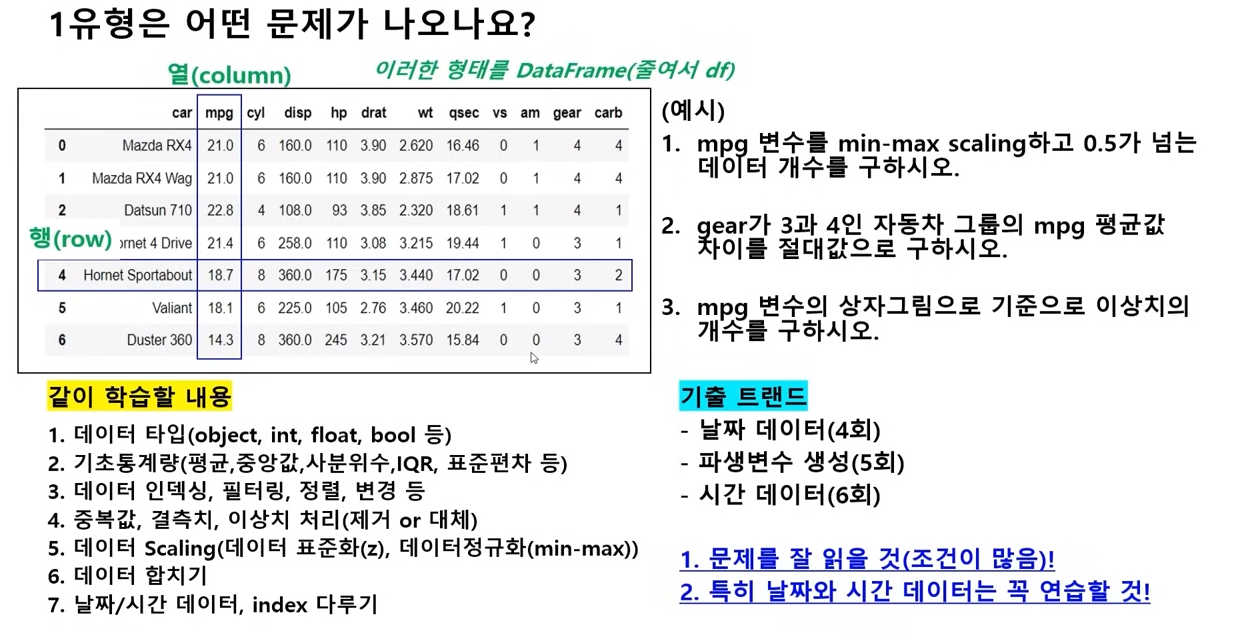
2유형은 만점을 받아야 안정권이다...

별도 응시 환경
공지사항에 패키지 확인하고 풀어야 함


# 데이터 불러오기
import pandas as pd
import numpy as np
df = pd.read_csv("파일 이름.csv")
df.head()
# 데이터 파입 확인
df.dtypes
# 데이터 타입 변경(1개)
df1 = df.copy() # 얕은 복사?
df1 = df1.astype({'cyl':'object'})
print(df1.dtypes)
# 데이터 타입 변경(2개 이상)
df1 = df1.astpye({'cyl':'int', 'gear':'object'})
print(df1.dtypes)
# df1에 어떤게 몇개 있는지
df1['cyl'].value_counts()
# 1) 중심측도를 나타내는 값(평균, 중앙값, 최빈값)
df.shape #(32, 12)
# 평균값
mpg_mean = df['mpg'].mean()
print(mpg_mean)
# 중앙값 구하기
mpg_median = df['mpg'].median()
print(mpg_median)
# 최빈값 구하기
mpg_mode = df['cyl'].mode() # 0 8
print(mpg_mode[0]) # 8
# 2) 산포도를 나타내는 값(분산, 표준편차, IQR, 범위(최대-최소) 등)
# 분산
mpg_var = df['mpg'].var()
print(mpg_var)
# 표준편차
mpg_std = df['mpg'].std()
print(mpg_std)
# IQR
Q1 = df['mqg'].quantile(.25) # 사분위수
print(Q1)
Q3 = df['mpg'].quantile(.75)
print(Q3)
IQR = Q3 - Q1
Q2 = df['mpg'].quantile(0.50)
# 범위(Range) = 최대값 - 최소값
mpg_max = df['mpg'].max()
mpg_min = df['mpg'].min()
mpg_range = mpg_max - mpg_min
print(mpg_range)
# 3) 분포의 비대칭도
# 왜도
mpg_skew = df['mpg'].skew()
# 첨도
mpg_kurt = df['mpg'].kurt()
# 4) 기타(합계, 절대값, 데이터 수 등)
# 합계
mpg_sum = df['mpg'].sum()
# 절대값
IQR2 = Q1 - Q3
print(abs(IQR2))
# 데이터 수
len(df['mqg'])
# 5) 그룹화하여 계산하기(groupby 활용)
# species 별로 각 변수의 평균 구해보기
import seaborn as sns
df = sns.load_dataset('iris')
df.head()
df.groupby('species').mean()
df.groupby('species').median()
df = pd.read_csv('mtcars.csv')
df.head()
# 1) 데이터 인덱싱
# 행/열 인덱싱 : df.loc['행', '열']
df.loc[3, 'mpg'] # 3이라는 인덱스 값 가져옴
# 열만 인덱싱
df.loc[:, 'mpg'].head()
df.loc[0:3, ['mpg', 'cyl', 'disp']]
df.loc[0:3, 'mpg':'disp']
# 앞에서 n행 인덱싱
df.head(n)
# 뒤에서 n행 인덱싱
df.tail(n)
# 3) 열(Columns) 추가/제거
# 열 선택
df_cyl = df['cyl'] # df.cyl
df_cyl.head()
df_new = df[['cyl', 'mpg']]
df_new.head(3)
# 열 제거
df.drop(columns=['car', 'mpg', 'cyl']).head(3)
# 열 추가
df2 = df.copy()
df2['new'] = df['mpg'] + 10
df2.head()
# 3) 데이터 필터링
# 1개 조건 필터링
# cyl=4인 데이터 수
cond1 = (df['cyl']==4)
# len(df[df['cyl'] == 4])
len(df[cond1])
# mpg가 22 이상인 데이터 수
cond2 = (df['mpg'] >= 22)
print(len(df['mpg']))
# 2개 조건 필터링
df[cond1 & cond2]
# 2개 조건 필터링 후 데이터 개수(and)
print(len(df[cond1 & cond2]))
# 2개 조건 필터링 후 데이터 개수(or)
df[cond1 | cond2]
print(len(df[cond1 | cond2]))
# 한번에 코딩할 경우
print(len(df[ (df['cyl'] == 4) & (df['mpg'] >= 22) ]))
# 4) 데이터 정렬
# 내림차순 정렬
df.sort_values('mpg', ascending=False).head()
# 오름차순 정렬(밑에서부터 올라간다)
df.sort_values('mpg', ascending=True).head()
# 5) 데이터 변경(조건문)
import numpy as np
df = pd.read_csv('mtcars.csv')
# np.where 활용
# hp 변수 값중에서 205가 넘는 값은 205로 처리하고 나머지는 그대로 유지
df['hp'] = np.where(df['hp'] >= 205, 205, df['hp'])
# 내림차순 정렬
df.sort_values('hp', ascending=False).head(10)
# 활용 : 이상치를 max값이나 min 값으로 대체할 경우 사용
import seaborn as sns
df = sns.load_dataset('titanic')
df.head()
df.shape
df.info()
# 1) 결측치 확인 및 처리
# 결측치 확인
df.isnull().sum()
# 결측치 제거
print(df.dropna(axis=0).shape) # 행기준
# 열기준 axis = 1
# 결측치 대체
# 데이터 복사
df2 = df.copy()
df2 = df.DataFrame(df)
# 1. 중앙값/평균값 등르로 대체
# 먼저 중앙값을 구합니다
median_age = df2['age'].median()
print(median_age)
# 평균으로 대체할 경우
mean_age = df2['age'].mean()
# 구한 중앙값으로 결측치를 대체합니다
df2['age'] = df['age'].fillna(median_age)
# 결측치가 잘 대체되었는지 확인합니다.
df2.isnull().sum()
# 중복값 확인
df.drop_duplicates().shape
# 2) 이상치 확인 및 처리
# 상자그림 활용(이상치 : Q1, Q3로 부터 1.5IQR을 초과하는 값)
# 타이타닉 데이터 불러오기
df = sns.load_dataset('titanic')
# (참고) 상자그림
sns.boxplot(df['age'])
# Q1, Q3, IQR 구하기
Q1 = df['age'].quantile(0.25)
Q3 = df['age'].quantile(0.75)
IQR = Q3 - Q1
upper = Q3 + 1.5 * IQR
lower = Q1 - 1.5 * IQR
print(upper, lower)
# 문제 : age 변수의 이상치를 제외한 데이터 수는? (상자그림 기준)
cond1 = (df['age'] <= upper) # 부호주의
cond2 = (df['age'] >= lower) # 부호주의
print(len(df[cond1 & cond2]))
print(len(df[cond1])) # lower 음수라서 모두 만족해서 넣어봄
print(len(df))
# 문제 : age 변수의 이상치를 제외한 데이터셋 확인(상자그림 기준)
df_new = df[cond1 & cond2]
print(df_new)
# 표준정규분호 활용(이상치 : +_3Z 값을 넘어가는 값)
# 데이터 표준화, Z = (개별값 - 평균) / 표준편차
mean_age = df['age'].mean()
std_age = df['age'].std()
print(mean_age)
print(std_age)
znorm = (df['age'] - mean_age) / std_age
znorm
# 문제 : 이상치의 개수는 몇개인가?(+_3Z기준)
cond1 = (znorm > 3)
len(df[cond1])
cond2 = (znorm < -3)
len(df[cond2])
print(len(df[cond1]) + len(df[cond2]))
# 중복값 제거
# 데이터 불러오기
df = sns.load_dataset('titanic')
df.shape
df1 = df.copy()
df1 = df1.drop_duplicates()
print(df1.shape)
# (주의) 예제에서는 중복값이 있어서 제거했지만
# 중복값이 나올 수 있는 상황이면 제거할 필요 없음
# 1) 데이터 표준화(Z-score normalization)
df = pd.read_csv('mtcars.csv')
df.head()
from sklearn.preprocessing import StandardScaler
zscaler = StandardScaler() # 변수명은 사용하기 편한 변수명으로 사용
df['mpg'] = zscaler.fit_transform(df[['mpg']])
df.head()
# 확인
print(df['mpg'].mean(), df['mpg'].std())
# 2) 데이터 정규화(min-max normalization)
df = pd.read_csv('mtcars.csv')
df.head()
from sklearn.preprocession import MinMaxScaler
mscaler = MinMaxScaler()
df['mpg'] = mscaler.fit_transform(df[['mpg']]_
df.head()
# 확인
print(df['mpg'].min(), df['mpg'].max())